재귀함수
재귀함수란 어떤 함수에서 자신을 다시 호출하여 작업을 수행하는 방식의 함수를 의미한다.
반복문을 사용하는 코드는 항상 재귀함수를 통해 구현하는 것이 가능하며 그 반대도 가능하다.
재귀함수를 작성할 때는 함수내에서 다시 자신을 호출한 후 그 함수가 끝날 때 까지 함수 호출 이후의
명령문이 수행되지 않는다는 사실과 종료조건이 꼭 포함되어야한다는 부분을 인지하고 작성하면
무한루프를 방지할 수 있다.
재귀함수 예제
public class PlusFunction {
public static void main(String[] args) {
HelloWorld(5); // HelloWorld 출력 메서드 호출
}
// HelloWorld 출력 메서드 선언
public static void HelloWorld(int n)
{
// n이 0인 경우 return
if(n == 0)
return;
System.out.println("HelloWorld"); // HelloWorld 출력
HelloWorld(n-1); // 재귀함수 시작
}
}
n이 0이 될 때 메소드를 종료하고, 함수를 호출 할 때마다 n을 1씩 빼서 재귀함수를 종료함
브루트포스 알고리즘
- 모든 경우의 수를 완전 탐색으로 구하는 알고리즘이다.
브루트포스 알고리즘의 방법으론
for문을 이용한 탐색, 재귀를 이용한 탐색
DFS&BFS 탐색 등이 있다.
전체를 탐색하는 알고리즘인 브루트포스는 좋은 알고리즘 방식이 아니다.
예를들어 1000억개의 자료를 검색할때에는 1000억개를 다 찾아봐야하기때문이다.
때문에 실제 알고리즘문제를 풀어나갈때에는 그 문제가 브루트포스로 가능한지 확인 후에 다른 알고리즘을 적용하여 해결해나아가야한다.
DFS & BFS 탐색
DFS(깊이우선탐색)
-자기 자신을 호출하는 순환 알고리즘의 형태를 지닙니다. (재귀 or 스택)
- 이 알고리즘을 구현할 때 가장 큰 차이점은 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야한다.
(검사하지 않을 경우 무한루프 빠질 위험 증가)
- 미로를 탐색할 때, 해당 분기에서 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 다시 가장 가까운 갈림길(새로운 분기)로 돌아와서 다른 방향으로 다시 탐색을 진행하는 방법과 유사
- 모든 노드를 방문하고자 할 때, 이 방법을 사용
- BFS에 비해서 속도는 느리지만 더 간단하게 사용 가능.
BFS(너비우선탐색)
-BFS는 재귀적으로 동작하지 않습니다.
-이 알고리즘 또한, 구현할 때 가장 큰 차이점은 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야한다
(검사하지 않을 경우 무한루프에 빠질 위험 증가 )
BFS는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐를 사용
시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법이다.
깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다.
두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 사용한다.
ex) 지구 상에 존재하는 모든 친구 관계를 그래프로 표현한 후 A와 B 사이에 존재하는 경로를 찾는 경우
DFS의 경우 - 모든 친구 관계를 다 살펴봐야 할지도 모른다.
BFS의 경우 - A와 가까운 관계부터 탐색한다.
정수론
- 각종 수의 성질을 대상으로 하는 수학의 한 분야
백준알고리즘을 푸는 도중, 정수론과 조합론에 관한 내용이 있어 찾아보았다.
프로그래밍에서 정수론은
1. 유클리드 호제법(최대공약수, 최소공배수)
2. 에라토스테네스의 체를 사용한 소수 찾기 및 소인수 분해
3. 거듭제곱과 모듈러 연산 등이 있다.
사실 더 있지만.. 알고리즘을 다 풀어보고 시간이 남지않는 이상은 더 찾아보지는 않을 듯 하다.
전체 글
- 재귀, 브루트포스, BFS, DFS 2022.11.01
- 백준 23505번문제 커트라인 2022.10.31
- 백준 2587번 문제 대표값2 2022.10.31
- 백준 2751번 문제 수 정렬하기2 2022.10.31
- 백준 2750번 문제 수 정렬하기 2022.10.31
- 토비의 스프링 3.1 1장 2022.10.31
- 정렬 리스트 2022.10.31
재귀, 브루트포스, BFS, DFS
백준 23505번문제 커트라인

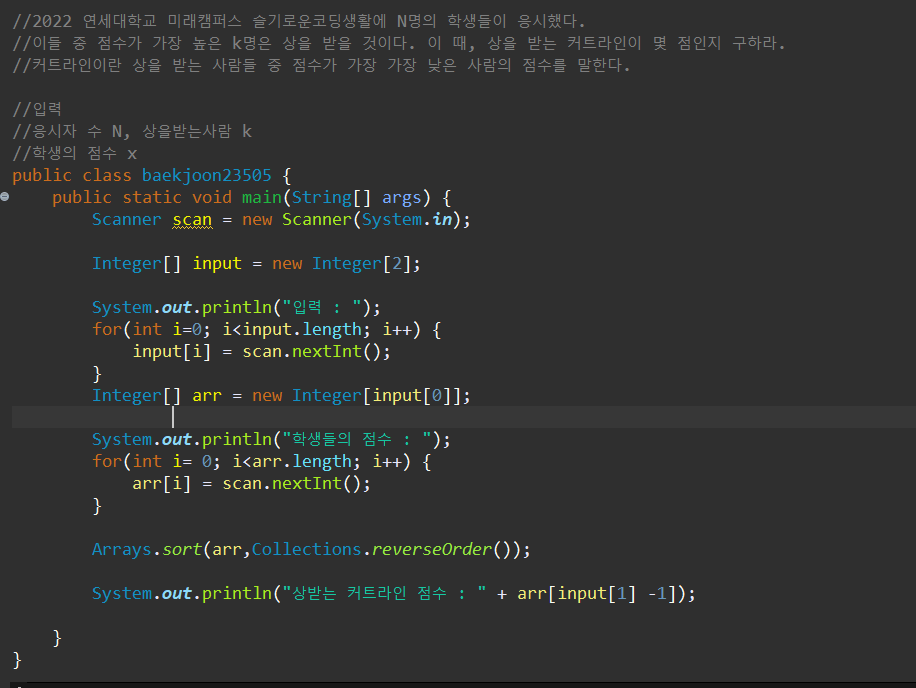
'문제풀이 > 백준' 카테고리의 다른 글
| 백준 2587번 문제 대표값2 (0) | 2022.10.31 |
|---|---|
| 백준 2751번 문제 수 정렬하기2 (0) | 2022.10.31 |
| 백준 2750번 문제 수 정렬하기 (0) | 2022.10.31 |
백준 2587번 문제 대표값2
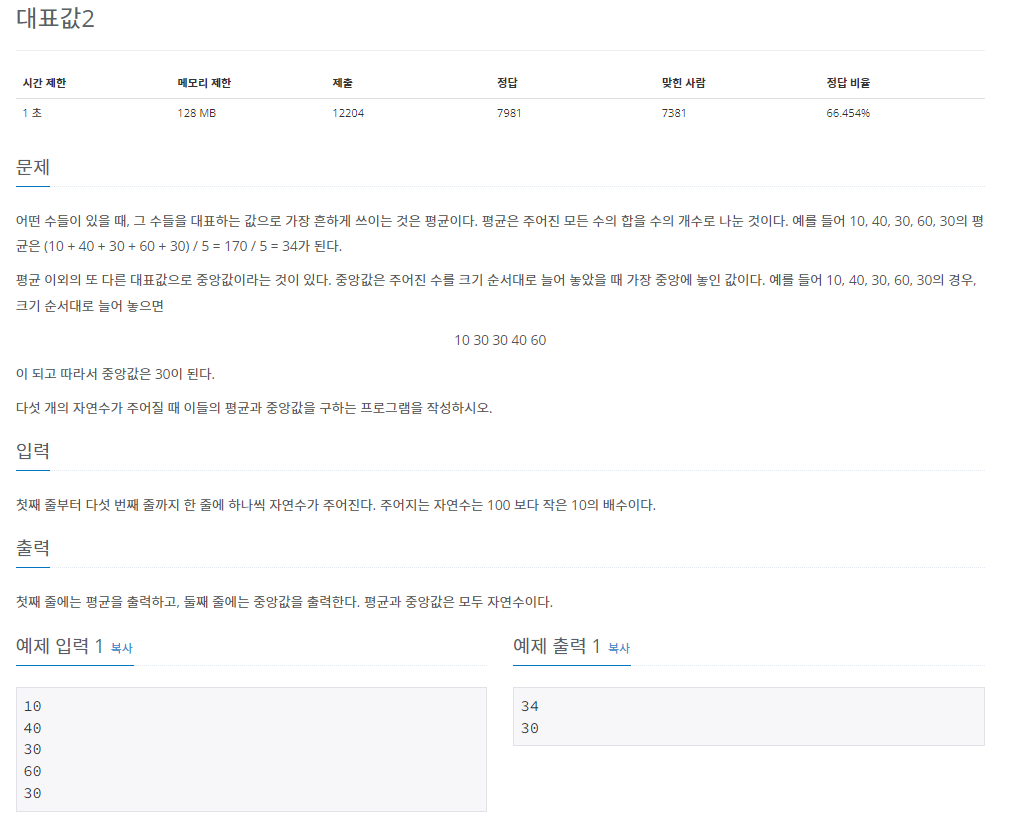
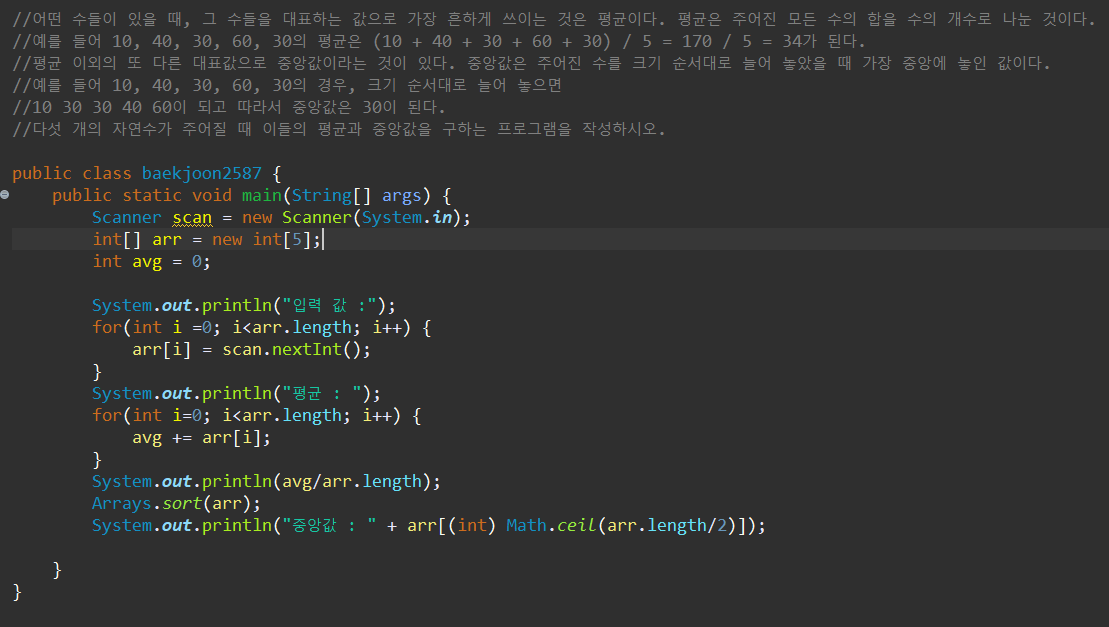
'문제풀이 > 백준' 카테고리의 다른 글
| 백준 23505번문제 커트라인 (0) | 2022.10.31 |
|---|---|
| 백준 2751번 문제 수 정렬하기2 (0) | 2022.10.31 |
| 백준 2750번 문제 수 정렬하기 (0) | 2022.10.31 |
백준 2751번 문제 수 정렬하기2


'문제풀이 > 백준' 카테고리의 다른 글
| 백준 23505번문제 커트라인 (0) | 2022.10.31 |
|---|---|
| 백준 2587번 문제 대표값2 (0) | 2022.10.31 |
| 백준 2750번 문제 수 정렬하기 (0) | 2022.10.31 |
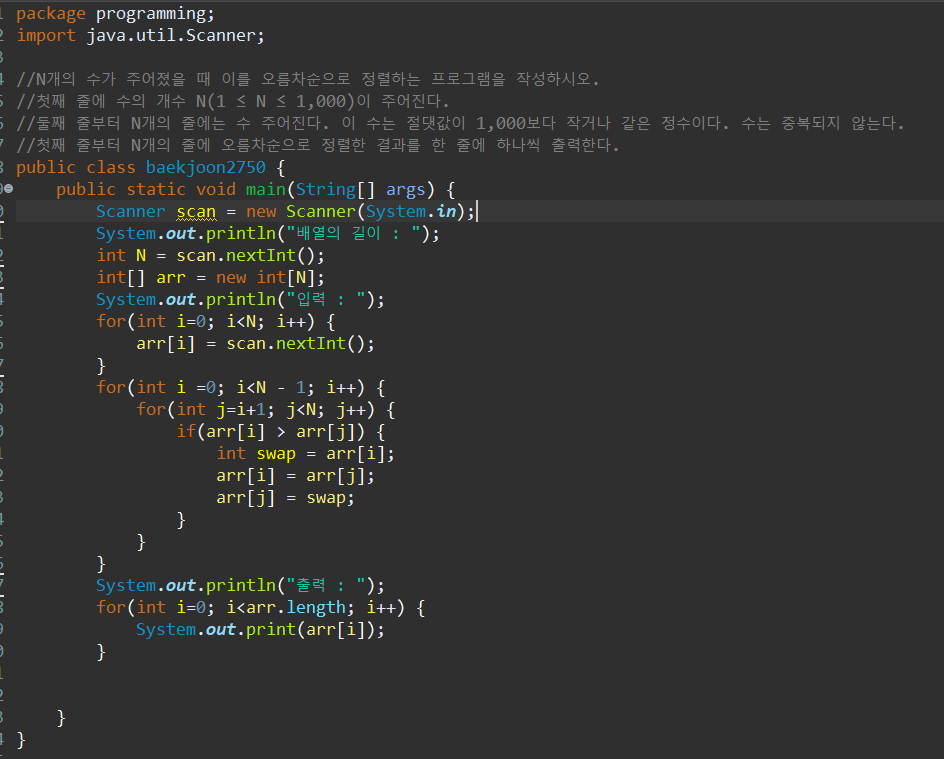
백준 2750번 문제 수 정렬하기
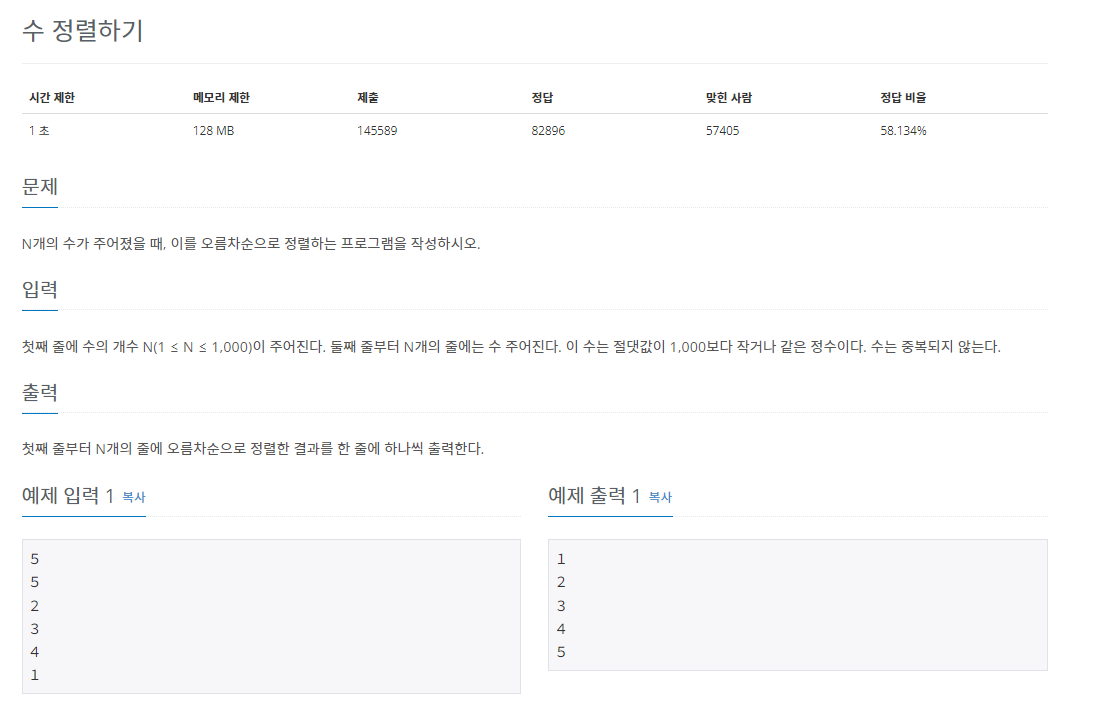
백준 2750번 수 정렬하기 문제이다.
선택정렬을 이용하여 문제를 풀어나갔으며, 정렬을 한번쯤은 해본사람이라면 누구나 쉽게 풀 수 있는 문제인것같다.
풀이
'문제풀이 > 백준' 카테고리의 다른 글
| 백준 23505번문제 커트라인 (0) | 2022.10.31 |
|---|---|
| 백준 2587번 문제 대표값2 (0) | 2022.10.31 |
| 백준 2751번 문제 수 정렬하기2 (0) | 2022.10.31 |
토비의 스프링 3.1 1장
1.1 초난감 DAO
DAO는 DB를 사용해 데이터를 조회하거나 조작하는 기능을 전담하도록 만든 오브젝트를 말한다.
JDBC를 이용한 등록과 조회 기능이 있는 UserDao 클래스를 만든다.
1.2 DAO의 분리
관심사의 분리 : 관심이 같은것끼리는 하나의 객체 안으로 또는 친한 객체로 모이게하고, 관심이 다른것들은 가능한 한
따로 떨어져서 서로 영향을 주지 않도록 분리 하는것
UserDao의 관심 사항
DB와 연결을 위한 커테션을 어떻게 가져올 것인가
사용자 등록을 위해 DB에 보낼 SQL 문장을 담을 Statement 를 만들고 실행.
작업이 끝나면 사용한 리소스인 Statement 와 Connection의 리소스 해제.
-> 하나의 관심사가 방만하게 중복되어 있고, 여기저기 흩어져 있어서 다른 관심의 대상과 얽혀 있으면, 변경이 일어날 때
엄청난 고통을 일으키는 원인이 된다.
중복 코드의 메소드 추출
DB연결과 관련된 부분에 변경이 일어났을 경우 getConnection() 이라는 한 메소드의 코드만 수정하도록 변경하였다.
관심의 종류에 따라 코드를 구분해 놓았기 때문에 한 가지 관심에 대한 변경이 일어 날 경우 그관심이 집중되는 부분의 코드만 수정하면 된다.
관심이 다른 코드가 있는 메소드에는 영향을 주지도 않을뿐더러, 관심 내용이 독립적으로 존재하므로 수정도 간단해 졌다.
상속을 통한 확장
UserDao에서 메소드의 구현 코드를 제거하고 getConnection()을 추상 메소드로 만들어 놓는다.
추상메소드로 만들게 되면 메소드 코드는 없지만 메소드는 존재하므로 UserDao의 소스코드를 수정하지 않아도
getConnection()메소드를 원한느 방식으로 확장한 후에 UserDao의 기능을 함께 사용할 수 있다.
기존에는 같은 클래스에 다른 메소드로 분리됐던 DB 커넥션 연결이라는 관심을 이번에는 상속을 통해 서브클래스로 분리했다.
클래스 계층 구조를 통해 두 개의 관심이 독립적으로 분리되면서 변경 작업은 한층 용이해졌다.
템플릿 메소드 패턴
- 슈퍼클래스에 기본적인 로직의 흐름을 만들고, 그 기능의 일부를 추상 메소드나 오버라이딩 가능한 protected 메소드 등으로 만든 뒤 서브클래스에서
이런 메소드를 필요에 맞게 구현해서 사용하도록 하는 방법을 템플릿 메소드 패턴 이라고 한다.
팩토리 메소드 패턴
- 템플릿 메소드 패턴과 유사하지만 서브클래스에서 구체적인 오브젝트 생성 방법을 결정하게 한 다는 점에서 다르다.
문제점
- 상속을 사용했기 때문에 다중 상속이 불가능한 자바에서는 후에 다른 목적으로 UserDao에 상속을 적용하기 힘들다.
- 상속관계는 두 가지 다른 관심사에 대해 긴밀한 결합을 허용한다. 서브클래스는 슈퍼클래스의 기능을 직접 사용 할 수 있다.
그래서 슈퍼클래스 내부의 변경이 있을 때 모든 서브클래스를 함께 수정하거나 다시 개발해야 할 수도 있다.
1.3 DAO의 확장
클래스 분리
- 관심사가 다르고 변화의 성격이 다른 이 두 가지 코드를 각각 분리한다.
- SimpleConnectionMaker라는 커넥션을 담당하는 오브젝트를 만든다.
- UserDao는 상속을 통한 방법을 쓰지 않으니 더 이상 추상적일 필요가 없다.
문제점
- DB커넥션을 제공하는 클래스가 어떤 것인지 UserDao가 구체적으로 알고 있어야 한다.
- 만약 커넥션을 제공하는 다른 클래스를 사용하고 메소드 명이 다를 경우 메소드의 커넥션을 가져오는 코드를 모두 다 수정해줘야하는 불편함이 있다.
- UserDao가 바뀔 수 있는 정보, DB커넥션을 가져오는 클래스에 대해서 너무 많이 알고 있다.
인터페이스 도입
- 두 개의 클래스가 서로 긴밀하게 연결되어 있지 않도록 중간에 추상적인 느슨한 연결고리를 만들어준다.
- 추상화란 어떤 것들의 공통적인 성격을 뽑아내어 이를 따로 분리해내는 작업이다.
- 인터페이스는 자신을 구현한 클래스에 대한 구체적인 정보는 모두 감춰 버리기 때문에 추상화 해놓은 최소한의 통로를 통해 접근하는 쪽에서는 오브젝트를 만들 때
사용할 클래스가 무엇인지 몰라도 된다.
문제점
- 초기에 한 번 어떤 클래스의 오브젝트를 사용할지를 결졍하는 생성자의 코드는 제거되지 않고 남아있다.
- UserDao가 인터페이스가 아니라 구체적인 클래스까지 알아야 한다.
관계설정 책임의 분리
-클래스 사이에 관계가 만들어지는 것이 아니고, 단지 오브젝트 사이에 다이나믹한 관계가 만들어지도록 한다.
-클래스 사이의 관계는 코드에 다른 클래스 이름이 나타나기 때문에 맘ㄴ들어지는 것이다. 하지만 오브젝트 사이의 관계는 그렇지 않다.
코드에서는 특정 클래스를 전혀 알지 못하더라도 해당 클래스가 구현한 인터페이스를 사용했다면, 그 클래스의 오브젝트를 인퍼에스 타입으로 받아서 사용할 수 있다.
-UserDao 오브젝트가 DCOnnectionMaker 오브젝트를 사용하게 하려면 두 클래스의 오브젝트 사이에 런 타임 사용관계 또는 링크, 또는 의존관계라고 불리는 관계를 맺어주면 된다.
-UserDao의 생성자를 다음과 같이 인터페이스 타입으로 받도록 수정하고, DCONnectionMaker를 생성하는 책임은 main()메소드로 넘긴다.
-UserDao는 자신의 관심사이자 책임인 사용자 데이터 액세스 작업을 위해 SQL을 생성하고, 이를 실행하는 데만 집중할 수 있게 됐다.
- 인터페이스를 도입하고 클라이언트의 도움을 얻는 방법은 상속을 사용해 비슷한 시도를 했을 경우에 비해 훨씬 유연하다. COnnectionMaker 라는 인터페이스를 사용하기만 한다면
다른 DAO클래스에도 ConnectionMaker의 구현 클래스를 그대로 적용할 수 있기 때문이다.
-DAO를 개선하며 사용한 OOP(객체지향) 기술들
1. OCP (개방폐쇄 원칙)
- 깔끔한 설계를 위해 적용 가능한 객체지향 설계 원칙 중의 하나로, 간단히 정의하자면 "클래스나 모듈은 확장에는 열려 있어야 하고 변경에는 닫혀 있어야한다." 이다.
(위의 코드에서 UserDao는 DB연결 방법이라는 기능을 확장하는데에는 열려 있고, 자신의 핵심 기능을 구현한 코드는 그런 변화에 영향을받지 않고 유지할 수 있으므로 변경에는 닫혀있다고 할 수 있다)
2. 낮은 결합도와 높은 응집도
1) 낮은 결합도
- 결합도란 "하나의 오브젝트가 변경이 일어날 때에 관계를 맺고 있는 다른 오브젝트에게 변화를 요구하는 정도"이다.
- 책임의 관심사가 다른 오브젝트 또는 모듈과 낮은 결합도를 유지하는 것이 바람직하다.
- 낮은 결합도란 결국, 하나의 변경이 발생할 때 마치 파문이 이는 것처럼 여타 모듈과 객체로 변경에 대한 요구가 전파되지 안흔ㄴ 상태를 말한다.
2) 높은 응집도
- 응집도가 높다는 것은 변화가 일어날 때 해당 모듈에서 변하는 부분이 크다는 것으로 설명할 수도 있다. 즉 변경이 일어날 때 모듈의 많은 부분이 함께 바뀐다면 응집도가 높다고 말할 수 있다.
- 만약 모듈의 일부분에만 변경이 일어나도 된다면, 모듈 전체에서 어떤 부분이 바뀌어야하는지 파악해야하고, 또 그 변경으로 인해 바뀌지 않느 부분에는 다른 영향을 미치지 않는지 확인해야 하는 이중의 부담이 생긴다.
3. 전략 패턴
- 자신의 기능 맥락에서, 필요에 따라 변경이 필요한 알고리즘을 인터페이스를 통해 통째로 외부로 분리시키고, 이를 구현한 구체적인 알고리즘 클래스를 필요에 따라 바꿔서 사용할 수 있게 하는 디자인 패턴이다.
- UserDaom는 전략 패턴의 컨텍스트에 해당한다. 컨텍스트는 자신의 기능을 수행하는데 필요한 기능 중에서 변경 가능한, DB 연결 방식이라는 알고리즘을 ConnectionMaker라는 인터페이스로 정의하고, 이를 구현한 클래스 즉 전략을 바꿔가면서 사용할 수 있게 분리 되어 있다.
1.4 제어의 역전(IOC)
UserDaoTest 는 기능이 잘 작동하는지 테스트를 하는 책임과 ConnectionMaker 구현 클래스를 만드는 책임까지 2가지의 책임을 가지고 있다.
이를 하나의 책임만 가지도록 분리 한다.
팩토리
- 객체의 생성방법을 결정하고 그렇게 만들어지는 오브젝트를 돌려주는 일을 하는 오브젝트.
오브젝트를 생성하는 쪽과 생성된 오브젝트를 사용하는 쪽의 역할과 책임을 깔끔하게 분리하려는 목적으로 사용한다.
UserDaoTest는 팩토리로부터 UserDao 오브젝트를 받아다가, 자신의 관심사인 테스트를 위해 활용하기만 하면 된다.
제어의 역전이란 제어 흐름의 개념을 거꾸로 뒤집는 것이다. 제어의 역전에서는 오브젝트가 자신이 사용할 오브젝트를 스스로 선택하지도,
생성하지도 않는다. 또 자신도 어떻게 만들어지고 어디서 사용되는지를 알 수 없다. 모든 제어 권한을 자신이 아닌 다른 대상에게 위임하기 때문이다.
제어의 역전 예시
1) 서블릿
- 서블릿에 대한 제어 권한으 가진 컨테이너가 적절한 시점에 서블릿 클래스의 오브젝트를 만들고 그 안의 메소드를 호출 한다.
2) 템플릿 메소드 패턴
- 제어권을 상위 템플릿 메소드에 넘기고 자신은 필요할 때 호출되어 사용되도록 한다는 제어의 역전 개념이 들어 있다.
3) 프레임 워크
- 애플리케이션 코드가 프레임워크에 의해 사용된다. 프레임워크 위에 개발한 클래스를 등록해두고, 프레임워크가 흐름을 주도하는 중에 개발자가 만든 애플리케이션 코드를 사용하도록 만드는 방식이다.
- 애플리케이션 코드는 프레임워크가 짜놓은 틀에서 수동적으로 동작해야 한다.
1.5 스프링의 IoC
스프링 용어 정리
1) bean
- 빈 또는 빈 오브젝트는 스프링이 IoC방식으로 관리하는 오브젝트라는 뜻이다.
- 스프링을 사용하는 애플리케이션에서 만들어지는 모든 오브젝트가 다 빈은 아니고 그 중에서 스프링이 직접 생성과 제어를 담당하는 오브젝트를 빈이라고 한다.
2) bean factory
- 스프링의 IoC를 담당하는 핵심컨테이너이다. 빈을 등록, 생성, 조회하고 이외에도 빈을 관리하는 기능을 담당한다.
- 보통은 이 빈 팩토리를 바로 사용하지 않고 이를 확장한 application context를 이용한다.
3) application context
- 빈 팩토리를 확장한 IoC 컨테이너다. 기본적인 기능은 빈 팩토리와 동일하고 여기에 스프링이 제공하는 각종 부가 서비스를 추가로 제공한다.
- 빈 팩토리라고 부를 때는 주로 빈의 생성과 제어의 관점에서 이야기하는 것이고, application context라고 할 때는 스프링이 제공하는 application 지원 기능을 모두 포함해서 이야기하는 것이라 보면 된다.
4) IoC컨테이너
- IoC 방식으로 빈을 관리한다는 의미에서 application conext나 bean factory를 IoC컨테이너라고 한다.
DaoFactory를 스프링에서 사용하기
- 스프링이 Bean Factory를 위한 오브젝트 설정을 담당하는 클래스로 인식할 수 있도록 @Configuration 어노테이션을 추가한다.
- 오브젝트를 만들어주는 메소드에는 @Bean이라는 어노테이션을 붙여준다.
애플리케이션 컨텍스트 적용
- 기존의 DaoFactory와 같은 팩토르 오브젝트에 대응되는 것이 스프링의 애플리케이션 컨텍스트다.
- DaoFactory와 달리 직접 오브젝트를 생성하고 관계를 맺어주는 코드가 없고, 그런 생성정보와 연관관계 정보를 별도의 설정정보를 통해 얻는다.
- @Configuration이 붙은 DaoFactory는 이 애플리케이션 컨텍스트가 활용하는 IoC설정 정보다.
- getBean()메소드는 ApplicationContext가 관리하는 오브젝트를 요청하는 메소드이다.
-@Bean이라는 어노테이션을 userDao라는 이름의 메소드 위에 붙이면 이 메소드의 이름이 바로 빈의 이름이 된다. 빈의 이름은 메소드 이름이 아닌 다른 이름으로도 사용할 수 있다.
애플리케이션 컨텍스트의 동작방식
-애플리케이션 컨텍스트는 DaoFactory 클래스를 설정정보로 등록해두고 @Bean이 붙은 메소드의 이름을 가져와 빈 목록을 만들어 둔다.
- 클라이언트가 애플리케이션 컨텍스트의 getBean()메소드를 호출하면 자신의 빈 목록에서 요청한 이름이 있는지 찾고, 있다면 빈을 생성하는 메소드를 호출해서 오브젝트를 생성시킨후 클라이언트에 돌려준다.
1.6 싱글톤 레지스트리와 오브젝트 스코프
오브젝트의 동일성과 동등성
- 자바에서는 두 개의 오브젝트가 완전히 같은 동일한 오브젝트라 말하는 것과, 동일한 정보를 담고 있는 오브젝트라고 말하는것은 분명한 차이가 있다.
- 전자는 동일성 비교라고하고, 후자를 동등성비교라고 한다. 동일성은 == , 동등성은 equals()메소드를 이용하여 비교한다.
- 스프링은 여러 번에 걸쳐 빈을 요청하더라도 매번 동일한 오브젝트를 돌려준다.
- 스프링은 기본적으로 별다른 설정을 하지 않으면 내부에서 생성하는 빈 오브젝트를 모두 싱글톤으로 만든다.
- application context는 싱글톤을 저장하고 관리하는 싱글톤 레지스트리이기도 하다.
- 싱글톤 레지스트리의 장점은 보통의 싱글톤 패턴에서와 같이 스태틱 메소드와 private 생성자를 사용해야 하는 비정상적인 클래스가 아니라 평범한 자바 클래스를 싱글톤으로 활용하게 해준다.
싱글톤과 오브젝트의 상태
- 기본적으로 싱글톤이 멀티스레드 환경에서 서비스 형태의 오브젝트로 사용되는 경우에는 상태정보를 내부에 갖고 있지 않은 무상태(stateless) 방식으로 만들어져야 한다.
다중 사용자의 요청을 한꺼번에 처리하는 스레드들이 동시에 싱글톤 오브젝트의 변수를 수정하는 것은 매우 위험하다.
싱글톤은 기본적으로 인스턴스 필드의 값을 변경하고 유지하는 상태유지(stateful) 방식으로 만들지 않는다. 물론 읽기전용의 값이라면 초기화 시점에서 인스턴스 변수에 저장해두고 공유하는 것은 아무 문제가 없다.
스프링 빈의 스코프
싱글톤 스코프는 컨테이너 내에 한 개의 오브젝트만 만들어져서, 강제로 제거하지 않는 한 스프링 컨테이너가 존재하는 동안 계속 유지된다.
프로토타입 스코프는 싱글톤과 달리 컨테이너에 빈을 요청할 때마다 매번 새로운 오브젝트를 만들어 준다.
그 외에 웹을 통해 새로운 HTTP 요청이 생길 때마다 생성되는 요청 스코프가 있고, 웹의 세션과 스코프가 유사한 세션 스코프도 있다.
1.7 DI
IoC 라는 용어는 매우 폭넓게 사용되는데, 스프링이 제공하는 IoC 방식을 좀 더 의도가 명확히 드러나는 의존관계 주입(DI, Dependency Injection)이라는 이름으로 부른다.
DI 는 오브젝트 레퍼런스를 외부로부터 제공(주입)받고 이를 통해 여타 오브젝트와 다이내믹하게 의존관계가 만들어지는 것이 핵심이다.
의존관계
- 두 개의 클래스 또는 모듈이 의존관계에 있다고 말할 때는 항상 방향성을 부여해줘야 한다. 즉 누가 누구에게 의존하는 관계에 있다는 식이여야 한다.
위의 그림에서는 A 가 B 에 의존하고 있음을 나타낸다.
의존한다는건 의존대상, 여기서는 B 가 변하면 그것이 A 에 영향을 미친다는 뜻이다. 반대로 B 는 A 에 의존하고 있지 않기 때문에 B 는 A 의 변화에 영향을 받지 않는다.
인터페이스에 대해서만 의존관계를 만들어두면 인터페이스 구현 클래스와의 관계는 느슨해지면서 변화에 영향을 덜 받는 상태가 된다. 결합도가 낮다고 설명할 수 있다.
의존관계란 한쪽의 변화가 다른 족에 영향을 주는 것이라고 했으니, 인터페이스를 통해 의존관계를 제한해주면 그만큼 변경에서 자유로워 진다.
의존관계 주입
- DI 컨테이너에 의해 런타임 시에 의존 오브젝트를 사용할 수 있도록 그 레퍼런스를 전달받는 과정이 마치 메소드(생성자)를 통해 DI 컨테이너가 주입해주는 것과 같다고 해서 이를 의존관계 주입이라고 부른다.
클래스 모델이나 코드에는 런타임 시점의 의존관계가 드러나지 않아야 한다. 그러기 위해서는 인터페이스에만 의존하고 있어야 한다.
런타임 시점의 의존관계는 컨테이너나 팩토리 같은 제3의 존재가 결정한다.
의존관계는 사용할 오브젝트에 대한 레퍼런스를 외부에서 제공(주입)해줌으로써 만들어진다.
정렬 리스트
시간복잡도, 공간복잡도
시간복잡도는 알고리즘의 절대적인 실행 시간을 나타내는 것이 아닌 알고리즘을 수행하는데
연산들이 몇 번 이루어지는지를 숫자로 표기 한다.
여기서 연산이란 산술, 대입, 비교, 이동을 말한다.
연산의 실행 횟수는 보편적으로 그 값이 변하지 않는 상수가 아니라 입력한 데이터의 개수를 나타내는 n에따라 변하게 된다. 연산의 개수를 입력한 데이터의 개수 n의 함수로 나타낸것을 시간복잡도 라고 말하며, 수식으로 T(n)이라고 표기한다.
공간복잡도는 프로그램을 실행시킨 후 완료하는 데 필요로 하는 자원 공간의 양을 말한다.
총 공간요구 = 고정 공간 요구 + 가변 공간 요구로 나타낼 수 있으며 수식으로는 S(P) = c + Sp(n)으로 표기.
여기서 고정 공간은 입력과 출력의 횟소누 크기에 관계없는 공간의 요구(코드 저장 공간, 단순 변수, 고정 크기의 구조 변수, 상수)를 말한다.
가변 공간은 해결하려는 문제의 특정 인스턴스에 의존하는 크기를 가진 구조화 변수들을 위해서 필요로 하는 공간, 함수가 순환 호출을 할 경우 요구가 되는 추가 공간을 말한다.
(동적으로 필요한 공간)
시간복잡도는 "얼마나 빠르게 실행되느냐" 이고,
공간복잡도는 "얼마나 많은 자원이 필요한가?" 이다.
좋은 알고리즘이란 시간과 자원의사용의 양이 적어야 하지만,
시간과 공간은 반비례적인 경향이 있기 때문에, 알고리즘의 척도는 시간 복잡도를 위주로 판단한다.
정렬 정리
1. 버블정렬
버블정렬은 서로 인접해있는 요소 간의 대소 비교를 통하여 정렬한다.
버블 정렬은 정렬 알고리즘 중 가장 단순한 알고리즘으로, 단순한 만큼 비효율적이다.
시간복잡도가 최고, 평균 최악 모두 O(N^2)이며 공간복잡도는 하나의 배열만 사용하므로 O(n)을 가진다.
동작방식은 인접한 두 요소간의 대소 비교를 진행한다.
2. 삽입정렬
삽입 정렬은 정렬을 진행할 원소의 index보다 낮은 곳에 있는 원소들을 탐색하며 알맞은 위치에 삽입해주는 정렬 알고리즘이다.
동작 방식은 두 번째 index부터 시작한다. 그 이유는 첫 번째 index는 비교할 원소가 없기 때문이다.
알고리즘이 동작하는 동안 계속해서 정렬이 진행되므로 반드시 왼쪽 맨 index까지 탐색하지 않아도 된다는 장점이 있다. 모두 정렬되어 있는 Optimal한 경우
모든 원소가 한 번씩만 비교되므로 O(n)의 시간 복잡도를 가진다. 또한 공간 복잡도는, 하나의 배열에서 정렬이 이루어지므로 O(n)이다.
3. 선택 정렬
선택 정렬은 배열에서 최소값을 반복저으로 찾아 정렬하는 알고리즘이다.
시간복잡도는 최선,평균,최악 모두 O(N^2)에 해당하는 비효율적인 알고리즘으로 정렬 여부와 상관없이 모든 경우의 수를 전부 확인한다.
동작방식 3단계로 구성된다. 첫 번째는 주어진 배열에서 최소 값을 찾은 후, 최소값을 맨 앞에 값과 바꾼다. 바꿔준 값을 제외한 나머지 원소를 앞의 방벙으로 바꿔준다.
4. 퀵 정렬
퀵 정렬은 분할정복법과 재귀를 사용해 정렬하는 알고리즘이다. 파이썬이나 자바 언어 자체에 내장되어 있는 알고리즘도 퀵 정렬을 기반으로 한다.
퀵 정렬에는 피봇이라는 개념이 사용된다. 피봇은 한마디로 정렬 될 기준 원소를 뜻한다. 피봇 선택 방법에 따라 퀵 정렬의 성능이 달라질 수 있다.
최적의 피봇 선택이 어려우므로 임의 선택을 해야 한다. 보통 배열의 첫번째 값이나 중앙 값을 선택한다.
5. 병합 정렬
병합 정렬은 분할정복과 재귀 알고리즘을 사용하는 정렬 알고리즘이다.
퀵 정렬과 함께 두 개의 알고리즘이 사용된다는 측면에서 공통점을 가진다. 하지만 차이점은 퀵 정렬이 피봇 선택 이후 피봇 기준으로 대소를 비교하는 반면,
병합정렬은 배열을 원소가 하나만 남을때 까지 계속 이분할 한 다음, 대소 관계를 고려하여 다시 재배열 하며 원래 크기의 배열로 병합한다.
6. 힙 정렬
힙을 알기전에 이진트리를 알아야하므로, 조금 정리해 보았다.
이진 트리란 컴퓨터 안에서 데이터를 표현할 때 데이터를 각 노드에 담은 뒤에 노드를 두 개씩 이어붙이는 구조를 말한다. 이때 트리 구조에 맞게 부모 노드에서 자식 노드로 가지가 뻗히는데,
이진 트리는 모든 노드의 자식노드가 2개 이하인 노드를 뜻한다.
완전 이진 트리는 데이터가 루트 노드부터 시작하여 자식 노드가 왼쪽 자식, 오른쪽 자식노드로 차근차근 뻗어가는 구조이다. 완전 이진 트리는 이진 트리의 노드가 중간에 비어있지 않고 빽빽히 가득 찬 구조를 말한다.
힙이란 트리 기반의 자료구조로서, 두 개의 노드를 가진 완전 이진 트리를 의미한다. 따라서 힙 정렬이란 완전 이진 트리를 기반으로 하는 정렬 알고리즘이다.
힙의 분류는 크게 최대 힙과 최소 힙 두 가지로 나뉜다. 최대 힙은 내림차순 정렬, 최소 힙은 오름차순 정렬에 사용한다.
최대힙의 경우 부모 노드가 항상 자식노드 보다 크다는 특징을 가진다. 반대로 최소힙의 경우 부모 노드가 항상 자식노드 보다 작다는 특징을 가진다. 이러한 힙에서
오해할 수 있는 특징은 힙은 정렬된 구조가 아니다. 부모 자식 간의 대소 관계에서만 나타내며 좌우 관계는 나타내지 않기 때문이다. 예를 들어 최소 힙에서 대부분
왼쪽 노드가 오른쪽 노드보다 작지만 4의 자식 노드인 7과 5는 왼쪽이 오른쪽보다 크다.
힙은 완전 이진 트리기 때문에 적절히 중간 레벨의 노드를 추출하면 중앙 값에 가까운 값을 근사치로 빠르게 추출할 수 있다는 장점을 갖고 있다. 때문에 힙은 배열에
순서대로 표현하기 적합하다. 또한 균형을 유지하려는 특징 때문에 힙은 우선순위 큐, 다익스트라, 힙 정렬, 프림 알고리즘에 사용된다.
7. 셀 정렬
셀 정렬은 삽입 정렬의 단점을 보완하고자 도입되었다. 삽입 정렬은 주어진 정렬 상태가 역순으로 배열되어 있을수록 비교횟수가 늘어나고, 최선의 경우 O(N)이지만 최악의 경우 O(N^2)이므로 성능 차이가 크다.
셀 정렬은 이러한 시간복잡도를 평균적으로 낮추고자 도입된 알고리즘이다. 셀 정렬에 사용되는 핵심 개년은 interval(간격)이다. interval은 비교할 원소 간의 간격을 의미한다. 셀 정렬에서는 비교 횟수를 줄이기 위해 interval은 큰 값에서
낮은 값으로 낮춰간다. 동작 방식은 배열에서 interval만큼 떨어진 원소들을 부분집합으로 구성한 뒤 삽입 정렬을 진행하는 방식으로 진행된다.
초기 interval 값은 배열 전체 길이의 / 2 이며 한번 정렬 시, interval 값을 2로 계속 나누어 준다.
만약 배열 length 가 8이라면, 첫번째 interval값은 4이고, 한번 정렬 시 2로 나누어 삽입정렬을 진행한다.
8. 기수 정렬
기수 정렬은 non-comparison 알고리즘으로 원소간의 대소 비교를 하지 않고 정려하는 알고리즘이다. 대신 기수 정렬은 정렬하고자 하는 수의 낮은 자리 수를 차례대로 확인하여 정렬하는 방식이다. 정렬을 위해 총 10개의 queue를 사용한다.
첫번째로, 1의 자리 수를 확인하여 각 원소의 1의 자리에 해당하는 queue에 쌓아준다.
두번째로, 10의 자리 수를 확인하여 각 원소의 10의 자리에 해당하는 queue에 쌓아준다.
n번째로, n의 자리수를 확인하여 각 원소의 n의 자리에 해당하는 queue에 쌓아주고,
이후 queue의 0~9를 순회하며 차례대로 가져온다.
8. 카운팅 정렬
카운팅 정렬은 non-comparison sort 알고리즘에 해당하는 알고리즘으로 comparison sort에 해당하는 버블, 선택, 힙, 병합, 퀵, 삽입이 기껏해야 평균적으로 O(nlogn)이나 O(n^2)의 시간복잡도를 갖기에 이를 O(n) 수준으로 낮추고자 도입된 알고리즘이다.
카운팅 정렬의 동작은 이름 그대로 배열에 존재하는 원소 별 개수를 세어 정렬하는 방식이다.
1)배열의 존재하는 값의 각 원소의 개수를 세어줄 새로운 배열 count를 만든다.
count의 길이는 원소의 최대값까지를 인덱스로 사용할 수 있도록 원소의 최대값 + 1만큼으로 지정해준다 (0을 포함)
count[i]는 숫자 i가 배열에 몇개 존재하는지에 대한 정보를 담는다.
2) count배열의 원소를 누적합으로 갱신해준다. 이 작업은 arr에 담긴 원소를 바로 정렬된 위치로 삽입하기 위한 사전작업이다.
ex) [0, 1, 1, 2, 2, 3] -> [0 , 1, 2, 4, 6, 9]
3) arr의 길이와 같은 result 배열을 만들어준다. 해당 배열에는 arr의 원소를 정렬된 위치에 삽입할 것이다.
4) arr의 각 원소값을 count의 인덱스로 사용해 값을 가져온 후, 해당 값을 다시 result의 인덱스로 사용해 arr의 원소로 저장해준다.
5) 해당 작업을 마친 후 count[arr[i]]의 값을 1 줄여준다.
카운팅 정렬은 정렬하고자 하는 배열의 최대값이 매우 클 때 메모리를 매우 비효율적으로 쓰게된다는 단점이 있다.
배열에 존재하는 원소의 개수를 기록해주기 위해서 최대값은 count배열을 만들어야하는데
만약 정렬해야하는 배열이 [1, 123011] 라면 단 2개의 숫자를 정렬하기위하여 10만이 넘는 길이의 배열을 만들어줘야하는 일이 생긴다.
이는 메모리차원에서 매우 비효율적이고, 또 인덱스를 통하여 숫자를 세어주는 방식이기 때문에, 배열에 음수가 존재한다면 사용이 불가능하다.
'알고리즘' 카테고리의 다른 글
| 재귀, 브루트포스, BFS, DFS (0) | 2022.11.01 |
|---|